Pocket Flow AI を通じてコードベースを理解しやすいチュートリアルに変換します。#
#AI #Codebase #Tools
GitHub - The-Pocket/PocketFlow-Tutorial-Codebase-Knowledge: Pocket Flow: Codebase to Tutorial
VoltAgent#
VoltAgent は、AI エージェントアプリケーションの開発を簡素化するオープンソースの TypeScript AI エージェントフレームワークです。さまざまな AI アプリケーションを迅速に構築するためのモジュール式の構成要素とツールを提供します。
#AI #Tools #Agents
メインフレーム時代から AI エージェントへ:真のパーソナライズ技術への長い旅#
Sean Falconer は、メインフレーム時代から AI エージェント時代への技術の進化と、その過程での個人の技術体験の発展について探ります。過去の技術革新は常によりパーソナライズされた体験を約束してきましたが、AI の登場まで、技術はユーザーに適応するのではなく、ユーザーが技術に適応することを強いていました。
1950 年代から 1970 年代のメインフレーム時代、コンピュータは巨大な共有マシンであり、ユーザーはマシンのルールに適応しなければなりませんでした。80 年代から 90 年代のデスクトップコンピュータ時代には、グラフィカルユーザーインターフェース(GUI)の登場により、ユーザーはアイコンやメニューをクリックして操作できるようになりましたが、ソフトウェアは依然としてユーザーの行動に基づいて学習し適応することができませんでした。その後、インターネットの普及により、ユーザーはブラウザを選択し、ウェブサイトを閲覧し、情報を検索できるようになりましたが、インタラクションは依然として十分にパーソナライズされておらず、推薦システムは一般的な傾向や広範なカテゴリに基づいていました。2000 年代のモバイル時代に入ると、スマートフォンはアプリとタッチスクリーン技術を通じて、ユーザーがいつでもどこでもパーソナライズされた情報を取得できるようにしましたが、このパーソナライズは依然としてルールに基づいており、真のインテリジェントな学習ではありませんでした。
AI の登場はこの状況を変えました。AI はユーザーの行動や好みに基づいてパーソナライズされたコンテンツを提供できるだけでなく、自然言語処理技術を通じてユーザーが最も自然な方法で技術と対話できるようにします。AI システムはユーザーの意図や行動パターンを学習することで、リアルタイムでユーザー体験を調整し最適化できます。たとえば、Spotify や Netflix は AI を利用してユーザーの行動データを分析し、パーソナライズされた音楽や映像コンテンツの推薦を提供し、ユーザーの参加度と満足度を大幅に向上させました。e コマース分野では、Amazon は AI 駆動の製品推薦システムを通じて、収益を 35%増加させました。Sephora は AI と拡張現実(AR)技術を組み合わせて、ユーザーにパーソナライズされた美容提案を提供し、ユーザーの参加度と転換率を向上させました。Nike の「Nike By You」プラットフォームは、AI を通じてユーザーにカスタマイズされた製品デザイン体験を提供しています。
AI 技術の急速な発展は、大規模言語モデル(LLM)、検索強化生成(RAG)、および適応システムなどの技術の支援によるものです。LLM は自然言語を理解し生成することができ、ユーザーが自然な方法でシステムと対話できるようにします。RAG 技術は、モデルが応答を生成する前にリアルタイム情報を検索することを可能にし、出力内容の正確性とタイムリーさを確保します。適応システムはユーザーの行動やフィードバックを監視することで、自身のパフォーマンスと推薦効果を継続的に最適化します。
AI 技術の進展に伴い、将来のアプリケーションはもはや単なるユーザーのサービスツールではなく、ユーザーと共に成長し進化するパートナーとなるでしょう。これらのアプリケーションは、ユーザーの行動や好みを学習し、リアルタイムでユーザー体験を調整し最適化することで、より自然で有用なインタラクション方法を提供します。しかし、技術のパーソナライズ度が高まるにつれて、その公平性、透明性、アクセス可能性を確保することが重要になり、すべてのユーザーがその恩恵を受けられるようにする必要があります。
#AI #思考 #ユーザー体験
メインフレームから AI エージェントへ:真のパーソナライズ技術への長い旅
OpenDeepWiki ソースコード解読#
#AI
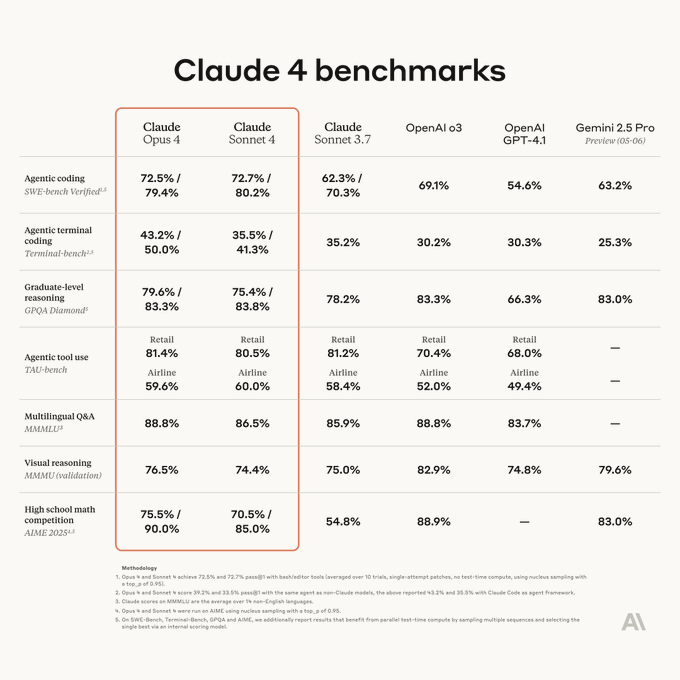
Claude 4 発表#
Claude 4 は Anthropic が発表した次世代 AI モデルで、Claude Opus 4 と Claude Sonnet 4 が含まれています。以下はその主な特徴のまとめです:
- 高度なプログラミング能力:Claude Opus 4 は現在最も強力なプログラミングモデルで、SWE-bench などのベンチマークテストで優れたパフォーマンスを発揮し、複雑なコーディングタスクを長時間処理でき、ナビゲーションエラー率は 20%からほぼ 0 に低下しました。20 以上のプログラミング言語をサポートし、コード生成とデバッグが可能で、複雑なコードベースの管理に適しています。
- 混合推論モード:即時応答と拡張思考の 2 つのモードを提供し、拡張思考モードは深い推論をサポートし、ツールの使用(例:ウェブ検索)を組み合わせて、複雑なタスクの応答品質を向上させます。
- 強化されたマルチモーダル能力:テキスト、画像処理をサポートし、動画コンテンツ分析や画像生成に拡張される可能性があり、メディア、教育、安全などの分野での応用に適しています。
- 拡張されたコンテキストウィンドウ:200K トークンのコンテキストウィンドウを維持(約 350 ページのテキスト)し、長文書や複雑な対話を処理するのに適しており、コンテキスト保持能力は前世代を上回ります。
- 高度な推論と問題解決:大学院レベルの推論(GPQA)、数学、論理タスクで優れたパフォーマンスを発揮し、推論能力は Claude 3.5 より 40%向上し、数学エラー率は 60%低下しました。
- 倫理と安全:Anthropic の憲法 AI アプローチを継承し、安全対策とバイアス緩和を強化し、AI の行動が責任を持ち、GDPR などの世界的規制に準拠することを保証します。
- 効率的なパフォーマンスとコスト:処理速度は 2.5 倍向上し、高パフォーマンスを維持しながらコスト効率が高く、価格は Opus 4($15 / 百万入力トークン、$75 / 百万出力トークン)と Sonnet 4($3 / 百万入力トークン、$15 / 百万出力トークン)です。
- エンタープライズ向けアプリケーション:SDK、リアルタイムデバッグ、オープンソースプラグインを提供し、クロスプラットフォーム統合をサポートし、小売、医療、教育などの業界の複雑なワークフローに適しています。データ分析、パーソナライズ体験、自動化タスクなど。
- 多言語サポートとグローバル化:多言語リアルタイム翻訳とコンテンツ生成をサポートし、グローバルなアクセス可能性を向上させます。
- ユーザー体験の最適化:ライティングスタイルをカスタマイズする「styles」機能を提供し、コンテンツ作成や技術文書をサポートします。「artifacts」機能はインタラクティブなコンテンツを生成します。長期タスクのメモリ最適化をサポートし、連続性を向上させます。
制限事項:視覚認識能力は Gemini 2.5 に劣る可能性があり、性能を最大限に引き出すためにはより正確なプロンプトエンジニアリングが必要です。
Claude 4 はプログラミング、推論、マルチモーダル能力において顕著な向上を示し、倫理的 AI とエンタープライズアプリケーションを強調し、深い推論と複雑なタスク処理が必要なシナリオに適しています。
#Claude #AI
Anthropic が Claude Opus 4 と Claude Sonnet 4 を発表。#
Claude Opus 4 は、これまでで最も強力なモデルであり、世界最高のコーディングモデルです。
Claude Sonnet 4 は前の製品に比べて大幅にアップグレードされ、卓越したコーディングと推論能力を提供します。
#Claude #AI
新しい生成メディアモデルとツールを活用して創造性を刺激する#
Google DeepMind チームは、創造性を刺激し、クリエイターにより多くの表現手段を提供することを目的とした一連の新しい生成メディアモデルとツールを発表しました。これらのモデルには Veo 3、Imagen 4、Flow が含まれ、画像、動画、音楽生成において顕著な進展を遂げ、アーティストが創造的なビジョンを現実に変える手助けをします。
Veo 3 は Google の最新の動画生成モデルで、Veo 2 を超える品質を持ち、初めて動画と音声の同期生成を実現しました。たとえば、都市の街並みのシーンで背景の交通音を生成したり、公園で鳥のさえずりを生成したり、キャラクター間の対話を生成することができます。Veo 3 はテキストと画像のプロンプト、リアルな物理効果、正確な口の動きの同期において優れたパフォーマンスを発揮し、ユーザーのストーリーの説明に基づいて対応する動画クリップを生成します。Veo 3 はその日、アメリカで Gemini アプリの Ultra サブスクリプションユーザーおよび Flow ユーザー向けに利用可能になり、企業ユーザーは Vertex AI でこのモデルを取得できます。
Imagen 4 は Google の最新の画像生成モデルで、速度と精度を兼ね備え、驚くべき詳細な画像を生成することができ、複雑な布地のテクスチャ、水滴、動物の毛皮などを正確に表現します。このモデルはさまざまなアスペクト比と最大 2K 解像度の画像生成をサポートし、印刷やプレゼンテーションに適しています。さらに、Imagen 4 はスペルやレイアウトの面でも顕著な改善があり、カード、ポスター、さらには漫画を簡単に作成できるようになりました。Imagen 4 は Gemini アプリ、Whisk、Vertex AI、Workspace のスライド、動画、文書などのツールで利用可能になり、Imagen 3 の 10 倍の速度で生成できる新しい高速バージョンも近日中に登場します。
Flow は Veo のために設計された AI 映画制作ツールで、Google DeepMind の最先端モデルである Veo、Imagen、Gemini を組み合わせています。ユーザーは自然言語でショットを説明し、ストーリーのキャラクター、シーン、アイテム、スタイルを管理し、これらの要素を美しいシーンに織り交ぜることができます。Flow はその日、アメリカで Google AI Pro および Ultra プランのサブスクリプションユーザー向けに利用可能になり、今後数ヶ月で他の国にも展開される予定です。
さらに、Google は音楽生成モデル Lyria 2 の更新を発表しました。これは音楽家、プロデューサー、作曲家に実験的なツールを提供し、新しい創作のインスピレーションを刺激します。Lyria 2 は現在、YouTube Shorts および Vertex AI を通じてクリエイターや企業ユーザーに開放されています。Google はまた、Lyria RealTime を発表しました。これはインタラクティブな音楽生成モデルで、リアルタイムで生成、制御、演奏でき、ユーザーは API または AI Studio を通じてこのモデルを使用できます。
責任ある創作に関して、Google は 2023 年以降、SynthID ウォーターマーク技術を使用して 100 億以上の画像、動画、音声ファイル、テキストにマークを付け、AI 生成コンテンツを識別し、偽情報や誤った帰属の可能性を減らす手助けをしています。Veo 3、Imagen 4、Lyria 2 が生成したコンテンツには引き続き SynthID ウォーターマークが付けられます。また、Google は SynthID Detector を発表しました。これは、ユーザーがコンテンツをアップロードして SynthID ウォーターマークが含まれているかどうかを確認できる検証ポータルで、AI 生成コンテンツかどうかを判断するのに役立ちます。
#Google #AI #Tools
Claude Code SDK#
Anthropic チームは Claude Code SDK を発表し、開発者が Claude Code 機能をアプリケーションに統合できるようにします。この SDK は現在コマンドラインでの使用をサポートしており、将来的には TypeScript および Python バージョンが登場する予定です。
基本的な使用方法として、開発者はコマンドラインで非対話モードで Claude Code を実行できます。たとえば、-p パラメータを使用してプロンプトを直接渡したり、パイプを介して入力を Claude Code に渡したりできます。また、出力形式をテキスト、JSON、またはストリーミング JSON に指定して、さまざまな開発ニーズに対応します。
高度な使用シナリオでは、SDK はマルチターン対話機能をサポートしており、開発者は最近の対話を続けたり、セッション ID を使用して特定の対話を復元したりできます。また、特定の役割(例:上級バックエンドエンジニアやデータベースアーキテクト)で回答するように Claude の行動を導くためにカスタムシステムプロンプトを使用することもできます。Model Context Protocol(MCP)設定により、開発者は Claude Code の機能を拡張し、外部サーバーが提供するツールやリソース(例:ファイルシステムアクセスや GitHub 統合)をロードできます。
CLI オプションとして、SDK は非対話モードの実行、出力形式の指定、セッションの復元、対話のターン数の制限、システムプロンプトの上書きまたは追加など、豊富なコマンドラインオプションを提供します。これらのオプションは、開発者に柔軟な制御能力を提供し、さまざまな開発シナリオに適応します。
出力形式はさまざまなタイプをサポートしています。デフォルトのテキスト出力は応答テキストのみを返します。JSON 出力には構造化データとメタデータ(コスト、持続時間、セッション ID など)が含まれます。ストリーミング JSON 出力はメッセージを逐次返し、マルチターン対話の処理に適しています。
メッセージアーキテクチャに関して、返されるメッセージは特定のパターンに厳密に従い、アシスタントメッセージ、ユーザーメッセージ、セッション初期化メッセージ、最終結果メッセージが含まれます。各メッセージタイプには、セッション ID、メッセージタイプ、サブタイプなどの特定のフィールドが含まれます。
ベストプラクティスとして、開発者にはプログラム解析を容易にするために JSON 出力形式を使用することが推奨され、終了コードやエラーログを確認してエラーを優雅に処理することが推奨されます。また、セッション管理機能を利用してマルチターン対話のコンテキストを維持し、必要に応じてタイムアウトを設定し、レート制限を遵守することが推奨されます。
実際のアプリケーションシナリオでは、Claude Code SDK は開発ワークフローに深く統合でき、たとえば GitHub Actions を通じて自動化されたコードレビュー、プルリクエストの作成、問題の分類などの機能を提供します。Anthropic チームは、開発者がこの SDK をより良く活用できるように、完全な CLI ドキュメント、チュートリアル、および関連リソースを提供しています。
#Claude #AI #SDK
ユーザー体験を良好に保ちながら、製品の転換率を向上させるには?#
ユーザーガイドデザインの目的は、ユーザーが製品を迅速に使い始められるようにし、使用のハードルを下げることですが、転換率を追求する過程で、時には「優しいコントロール」に変わり、ユーザーの基本的な権利を侵害する可能性があります。たとえば、一部の製品では、ユーザーに会員登録を促す際に「3 日間の無料トライアル後に自動更新」の条項を非常に小さく記載し、サブスクリプションをキャンセルするプロセスが非常に複雑です。このようなデザインは短期的には転換率を向上させるかもしれませんが、長期的にはユーザーの信頼感を損ない、法律に違反するリスクを伴う可能性があります。
ユーザー体験と転換率のバランスを実現するために、DesignLink は以下の提案を行っています:
- ユーザーの選択権を尊重する:デザインはユーザーに本当に選択の権利を持たせるべきであり、視覚的またはインタラクション手段でユーザーに決定を強いるべきではありません。たとえば、「同意」ボタンを目立たせすぎず、「拒否」オプションを隠したり弱めたりするべきではありません。また、明確な退出経路を提供し、ユーザーが簡単に操作をキャンセルしたり、後で決定したりできるようにします。
- ユーザーの情報透明権を保障する:ユーザーの権限を要求したり、データを収集したりする際には、目的、内容、結果を明確に伝える必要があります。たとえば、ユーザーのマイクやカメラにアクセスする必要がある場合は、その用途を明確に説明し、「より良いサービス体験のため」といった曖昧な理由でユーザーを混乱させるべきではありません。また、ユーザー契約などの重要な情報は、わかりやすい言葉で記載し、複雑な法律用語を避けるべきです。
- ユーザーにデータ管理権を与える:ユーザーは自分のデータを簡単に管理できるべきであり、エクスポート、変更、削除ができるようにします。製品デザインには、ユーザーが自分のデータをいつでも確認し、制御できる便利なデータ管理機能を提供する必要があります。
- 退出およびキャンセルプロセスを最適化する:サブスクリプションをキャンセルしたりサービスを退出するプロセスは簡潔で明確であるべきであり、過剰な障害を設定すべきではありません。たとえば、ユーザーがサブスクリプションをキャンセルする際に複雑なアンケートに記入したり、カスタマーサポートに連絡したりする必要がないように、一括キャンセル機能を提供するべきです。また、キャンセル後はユーザーのデータアクセス権を一定期間保持し、ユーザーがいつでもサービスを再開できるようにします。
デザイン倫理はユーザー体験デザインにおいて非常に重要です。デザイナーはユーザー中心で考え、ユーザーが製品を使用する際に安心感、自由、尊重を感じられるようにする必要があります。たとえば、登録、支払い、共有などの重要なポイントをデザインする際には、明確でわかりやすいオプションを提供し、二重確認メカニズムを設定して、ユーザーが誤操作で後悔しないようにします。
DesignLink は持続可能な体験と権利のバランスモデルを構築する方法を提案しています。たとえば、「三段階デザインレビュー機構」を採用し、機能を公開する前にユーザーがその機能を本当に必要としているかを確認し、中間でユーザーがガイドプロセスを自分で管理できているかをチェックし、後期にはユーザーのフィードバックを収集して製品を継続的に最適化します。また、デザインモデルは公平性、説明可能性、可逆性、フィードバック性を備え、すべてのユーザーがスムーズに製品を使用でき、いつでも後悔したり意見を述べたりできるようにする必要があります。
#ユーザー体験 #体験デザイン
万字干貨!ユーザー体験を良好に保ちながら、製品の転換率を向上させるには?
Google Stitch#
Google は Stitch を発表しました。これは優れたデザインと UI インターフェースを生成する最も簡単で迅速な製品です。
Stitch は AI 駆動のツールで、アプリケーションビルダーがモバイルおよび Web アプリケーションの高品質なユーザーインターフェースを生成し、Figma に簡単にエクスポートしたり、フロントエンドコードに直接アクセスしたりできるようにします。
#Google #AI
Google は本日 I/O 2025 カンファレンスで一連の新しい AI モデル、ツール、サブスクリプションサービスを発表しました#
生成メディア
- Veo 3 は Google の最先端の動画生成モデルで、音声や対話を伴う動画を作成でき、現在アメリカでは Google AI Ultra サブスクリプションユーザーが Gemini アプリと Flow を通じて利用でき、Vertex AI でプライベートプレビューも可能で、今後数週間でより広範に展開される予定です。
- Veo 2 は新機能を獲得しており、スタイルとキャラクターの一貫性を保つための参照駆動の動画、正確なショット調整のためのカメラ制御、アスペクト比を拡張するための外画、オブジェクトの追加 / 削除などが含まれています。現在 Flow で新しいコントロールが提供されており、Vertex AI では全コントロールが近日中に提供される予定です。
- Imagen 4 はより豊かで詳細かつ正確な画像を生成でき、テキストレンダリングと迅速な結果を改善し、現在 Gemini アプリ、Whisk、Workspace(スライド、文書、動画)、Vertex AI で無料で提供されており、新しい高速バージョンも近日中に登場します。
- Flow は新しい AI 映画制作ツールで、自然言語と資産管理を通じて Veo、Imagen、Gemini を使用して映画クリップを作成できます。現在、アメリカの Google AI Pro および Ultra サブスクリプションユーザーが利用可能です。
- Google の音楽生成モデル Lyria 2 は現在 Vertex AI で利用可能で、高忠実度の適応音楽生成を行い、Lyria RealTime は実験的なインタラクティブ音楽モデルとして Gemini API および Google AI Studio を通じて使用でき、リアルタイムで生成音楽の創作と演奏が可能です。
Gemini アプリ
- Canvas にはワンクリックで「作成」ボタンが追加され、チャット内容をインフォグラフィック、クイズ、45 言語のポッドキャストなどのインタラクティブコンテンツに簡単に変換できるようになりました。また、Deep Research ではファイルや画像をアップロードできるようになり、Google Drive や Gmail との統合も近日中に登場します。
- Gemini Live のカメラと画面共有機能は、Android および iOS で無料で提供されており(展開中)、カレンダー、Keep、マップ、Tasks などの Google アプリとの統合も近日中に行われる予定です。
サブスクリプション
- Google AI Pro(毎月 19.99 ドル)はアメリカおよび他の国で利用可能ですが、最新機能(Chrome での Flow や Gemini など)は最初にアメリカで展開され、より広範に展開される予定です。
- Google AI Ultra(249.99 ドル / 月、新規ユーザーは最初の 3 ヶ月 50%オフ)は最高の使用制限を提供し、Veo 3 や Gemini 2.5 Pro Deep Think などの高度なモデルを最初に使用でき、最高制限の Flow、Agent Mode の独占使用、YouTube Premium および 30TB のストレージを提供し、現在アメリカで展開中で、他の国でも近日中に展開される予定です。
- アメリカ、イギリス、ブラジル、インドネシア、日本の大学生は、1 年間無料で Google AI Pro を利用できます。
Chrome およびエージェントモードの Gemini
- Chrome の Gemini はデスクトップで展開中で、アメリカ(英語)の Google AI Pro および Ultra ユーザーが利用でき、読んでいるウェブページの要約、明確化、支援を受けられ、プライバシーコントロールにより、Gemini はユーザーが要求したときのみ行動します。
- エージェントモードは Ultra デスクトップユーザー向けに近日中に展開され、Gemini が MCP プロトコルを使用してオンラインで複雑な目標を自動的にナビゲートすることを可能にします。たとえば、リストのフィルタリング、フォームの記入、検索結果に基づくスケジュール作成などが含まれます。
検索における AI の活用
- AI モードは新しいタブとして Google 検索で全アメリカユーザーに展開され、Gemini 2.5 によってサポートされ、より高度な推論、長いクエリ、マルチモード検索、高品質な即時回答を提供します。「深い検索」機能は数百回の検索を同時に行い、引用を統合したレポートを提供します。
- Project Astra のリアルタイム機能(カメラを指して、見ている内容を尋ねる)、Project Mariner のエージェントツール(チケット購入、予約、タスク管理)、Gmail や他の Google アプリの個人コンテキストが AI モードに統合され、ユーザーが制御します。
Gemini 2.5
- Gemini 2.5 Pro および 2.5 Flash は、コーディングおよび推論のベンチマークでリーダーであり、Gemini 2.5 Flash には新しいプレビュー版があり、より良い速度、効率、コーディング / 推論能力を備えています。両モデルは 2025 年 6 月に全面的に展開される予定です。
- Gemini 2.5 Pro Deep Think は、複雑なタスクのための並列思考技術を含む実験的な強化推論モードを導入し、全面的に展開される前に、まず Gemini API を通じて信頼できるテストユーザーに提供され、ユーザーが回答の深さと速度を制御できる思考予算を提供します。
- Gemini API および SDK は、モデルコンテキストプロトコル(MCP)をネイティブにサポートし、エージェントやツールをシステム間で統合しやすくします。
- Gemini API および Vertex AI は現在「思考の要約」を提供し、Gemini の推論とツールの使用を段階的に説明します。
Project Starline -> Google Beam、Astra -> Gemini Live、Mariner -> エージェントモード
- Starline プロジェクトは Google Beam に改名され、AI 駆動の 3D ビデオ通話プラットフォームで、2D ストリーミングを没入感のあるリアルな会議に変換します。これは今年後半に HP や他の企業パートナーと協力して展開される予定です。
- Gemini Live には Astra のリアルタイムカメラと画面共有機能が組み込まれており、これらの機能は Android で無料で提供され、iOS でも展開されています。
- Project Mariner のエージェントコンピュータ使用機能(例:マルチタスク処理やブラウザの自動化)は、現在アメリカの Ultra ユーザーに開放され、近日中に Gemini API および Vertex AI を通じて開発者に開放される予定です。
オープンモデルと開発ツール
Gemma 3n は、迅速で低メモリデバイス向けに設計された新しい効率的なマルチモーダルオープンモデルで、テキスト、音声、画像、多言語入力をサポートし、現在 AI Studio および AI Edge で開発者向けにプレビュー版が提供されています。
- Jules は、Gemini 2.5 Pro によってサポートされる非同期コーディングエージェントで、現在公開テスト中であり、無料で GitHub またはリポジトリで実際のコーディングタスクを処理し、同時タスクと音声更新ログを備えています。
- Gemini Diffusion は、迅速なテキスト生成のための実験的研究モデルで、その出力速度は Google の以前の最速モデルの約 5 倍です。現在、開発者向けに候補者リストを通じてプレビュー版が提供されています。
SynthID Detector は、画像、音声、動画、またはテキストが Google の AI ツールによって生成されたかどうかを確認するためのポータルで、現在候補者リストを通じて初期テストユーザーに提供され、今後より広範なアクセスが提供される予定です。
AlphaEvolve:Gemini に基づくコーディングエージェント、高度なアルゴリズムの設計#
AlphaEvolve は、Gemini モデルに基づく進化型コーディングインテリジェントエージェントで、一般的なアルゴリズムの発見と最適化に特化しています。AlphaEvolve は、Gemini Flash と Gemini Pro の 2 つの大規模言語モデル(LLM)の能力を組み合わせており、前者は広範な探索に重点を置き、後者は深い提案を提供し、アルゴリズム解決策を実現するためのコンピュータプログラムコードを共同で提案します。自動評価者による検証、実行、スコアリングを通じて、AlphaEvolve は数学やコンピュータサイエンスなどの定量的な分野で優れたパフォーマンスを発揮します。
AlphaEvolve は Google の計算エコシステムにおいて重要な役割を果たしており、データセンターのスケジューリング、ハードウェア設計、AI モデルのトレーニングなどに利用されています。たとえば、Google の Borg システムに対して効率的なヒューリスティックアルゴリズムを発見し、Google のグローバル計算リソースの平均回復率を 0.7%向上させ、データセンターの効率を大幅に向上させました。ハードウェア設計においても、AlphaEvolve は Google のテンソル処理ユニット(TPU)に対して最適化提案を行い、行列乗算の効率を向上させました。さらに、GPU 命令を最適化することで、Transformer モデル内の FlashAttention コアにおいて最大 32.5%の加速を実現しました。
数学とアルゴリズムの発見の分野でも、AlphaEvolve は画期的な進展を遂げました。行列乗算のための新しい勾配最適化プロセスを提案し、さまざまな新しいアルゴリズムを発見しました。たとえば、4×4 の複素行列を掛け算するのにわずか 48 回のスカラー乗算で済むアルゴリズムを見つけ、以前は最適と考えられていた Strassen アルゴリズムを上回りました。さらに、AlphaEvolve は 50 以上の数学的分析、幾何学、組合せ論、数論のオープン問題をテストし、約 75%のケースで既知の最適解を再発見し、20%のケースで既知の最良解を改善しました。たとえば、11 次元空間における「キス数問題」の新しい下限を確立しました。
#Google #AI #Gemini #Agents
AlphaEvolve:高度なアルゴリズム設計のための Gemini 駆動のコーディングエージェント
SMS 2FA は安全でないだけでなく、山間部の住民に優しくない#
stillgreenmoss は、ノースカロライナ州西部の山間部に住む高齢女性が SMS 二要素認証(SMS 2FA)によって直面している問題を説明しています。この女性は山間部に住んでおり、町からわずか 20 分の距離にありますが、地形のために安定した携帯信号を受信できません。彼女は Spectrum が提供するネットワークサービスと携帯プランを使用していますが、山間部の信号カバレッジが不十分なため、アカウントにログインするための SMS 確認コードを受信できず、電子メール、銀行口座、医療サービスなどの重要なサービスにアクセスできません。
彼女は携帯電話の Wi-Fi 通話機能を有効にしましたが、5 桁のショートコードからの SMS 確認コードは Wi-Fi 経由で受信できないことがわかりました。stillgreenmoss はさらに調査し、特定のインターネットサービスプロバイダー(ISP)が提供する固定電話サービスが SMS を受信し、コンピュータ音声で読み上げることができることを発見しましたが、Spectrum はそのようなサービスを提供していませんでした。彼女は、SMS 2FA に依存するすべてのアカウントを時間ベースのワンタイムパスワード(TOTP)認証に変更する必要がありましたが、そのためにはまずアカウントにログインして設定を変更する必要があります。したがって、彼女は SMS 2FA のためにアクセスできないすべてのウェブサイトをリストアップし、友人と会う約束をし、町に行き、友人の助けを借りてこれらのアカウントを TOTP 認証に変更しました。しかし、一部のウェブサイトは TOTP をサポートしておらず、彼女はこれらの会社に連絡してアカウントの SMS 2FA 機能を無効にするように依頼する必要がありましたが、現在は会社に連絡するのが非常に難しいことがわかりました。
stillgreenmoss は、他の解決策として、携帯電話番号を Wi-Fi でショートコード SMS を受信できる VoIP プロバイダーに移行することや、数百ドルをかけて自宅の外に携帯信号ブースターを設置すること、さらには引っ越しを検討することなどが挙げられますが、これらの選択肢は非常に非現実的です。また、TOTP は代替手段ですが、専用のアプリをダウンロードする必要があり、ユーザーはアプリを選択する際に多くの高リスクな選択肢や複雑な技術的説明に直面します。
SMS 2FA はユーザー体験の面では良好であり、技術的には十分に安全ですが、山間部での適用性は非常に低いとされています。ノースカロライナ州西部の山間部には 110 万人が住んでおり、アパラチア全体では 2500 万人が住んでおり、西部山脈や太平洋沿岸山脈に住む人々も同様の携帯信号カバレッジ不足の問題に直面しています。stillgreenmoss は、これらの地域にはインターネット接続があるにもかかわらず、F レベルの携帯信号カバレッジがあるため、SMS 2FA はこれらのユーザーにとってほとんど使用できないことを疑問視しています。これは、特定の地理的環境における SMS 2FA の限界を浮き彫りにしています。
#2FA #安全
SMS 2FA は安全でないだけでなく、山間部の人々にとっても敵対的です — stillgreenmoss
PDF からテキストへの変換、挑戦的な問題#
Marginalia は、PDF ファイルからテキスト情報を抽出する複雑さと、検索エンジン最適化のためのテキスト抽出方法について探求しています。チームは、PDF ファイルは本質的にテキスト形式ではなくグラフィック形式であり、その内容は紙上の座標にマッピングされた文字であり、文字は回転、重なり、順序が混乱しており、意味情報が欠如しているため、テキストの抽出が非常に困難であると指摘しています。それにもかかわらず、ユーザーは PDF ビューアで検索機能を使用できること自体が驚くべき成果です。
検索エンジンはクリーンな HTML 形式の入力を受け取ることを好み、現在の最良の PDF からテキストへの方法は視覚に基づく機械学習モデルである可能性がありますが、この方法は GPU なしで数百 GB の PDF ファイルを処理するのが難しいです。したがって、チームは Apache PDFBox の PDFTextStripper クラスから始めました。このクラスは PDF 内のテキストを抽出できますが、タイトルなどの意味情報を認識できないなどの多くの制限があります。これらの情報は検索エンジンにとって非常に重要です。
PDF からテキスト抽出を検索エンジンのニーズにより適合させるために、チームは多くの改善を行いました。タイトルを認識するための簡単な方法は、半太字またはそれ以上の太さのテキスト行を探すことですが、すべてのタイトルが太字フォントを使用しているわけではなく、多くのタイトルはフォントサイズに依存して区別されます。異なる文書のフォントサイズの違いが大きいため、タイトルと本文を区別するためのグローバルな断点を見つけることはできず、各ページに対してフォントサイズの統計情報を構築する必要があります。ページのフォントサイズ分布を分析することで、各ページには通常、支配的なフォントサイズがあり、これは本文のフォントサイズです。タイトルを抽出する際には、ページの中央値フォントサイズの 20%を因子として使用することで、タイトルを比較的信頼性高く識別できることがわかりましたが、いくつかの例外もあります。
さらに、タイトルは時々複数行に分かれることがあり、チームは連続するタイトル行を 1 行に統合しようとしましたが、この操作の決定は複雑です。たとえば、特定のタイトルが右揃えである場合や、タイトルの下に著者名などの他の太字テキストが続く場合など、これらの状況はタイトルの統合を困難にします。それにもかかわらず、同じフォントサイズと重みを持つ連続するタイトル行を統合することは通常良好な結果を得ることができますが、いくつかの望ましくない結果も生じます。
段落を認識する際、PDFTextStripper は行間隔とインデントを分析して段落の分割を判断することで良好なパフォーマンスを発揮しますが、その行間隔のロジックには改善の余地があります。このツールは固定の行間隔の断点を使用しており、異なる文書の行間隔の違いを考慮していません。特に学術草稿やプレプリントでは 1.5 倍から 2 倍の行間隔が一般的です。行間隔の値が大きすぎると、タイトルの認識を妨げ、いくつかのタイトルが本文段落に誤って分類される可能性があります。この問題を解決するために、チームは再びフォントサイズと同様の統計的方法を採用しました。ページテキストの行間隔分布を分析することで、中央値の行間隔が本文テキストで使用される行間隔であることがわかり、これを基に因子を追加することで、任意の行間隔に適応可能な段落分離のヒューリスティック手法を得ることができます。
PDF からテキストを抽出することは決して完璧ではありません。なぜなら、この形式はテキスト抽出のために設計されておらず、「十分良い」解決策を選択する際にはトレードオフが必要だからです。検索エンジンは主に関連性信号に注目しており、たとえばタイトルを認識し、要約を識別し、残りのテキストの構造を大まかに理解できれば、比較的優雅な解決策と見なされます。
#PDF #実践
GitHub Copilot コーディングアシスタントの公開プレビュー版#
GitHub Copilot コーディングアシスタントは 2025 年 5 月 19 日に正式に公開プレビュー段階に入り、開発者に新しいプログラミング体験を提供します。開発者は、他の開発者に割り当てるように Copilot に問題を割り当てることができ、Copilot はバックグラウンドで実行され、GitHub Actions が提供するクラウド開発環境を利用してコードリポジトリを探索し、変更を加え、テストとコード規範の検証を経てコードを提出します。タスクが完了すると、Copilot は開発者にコードレビューを通知し、開発者はプルリクエストにコメントを残して Copilot に修正を要求したり、ローカルブランチで開発を続けたりできます。Copilot は全過程でサポートします。
Copilot は、低から中程度の複雑さのタスクを処理する際に優れたパフォーマンスを発揮します。たとえば、十分にテストされたコードベースに機能を追加したり、バグを修正したり、テストを拡張したり、コードをリファクタリングしたり、ドキュメントを改善したりすることができ、複数の問題を同時に処理することも可能です。この機能は現在、Copilot Pro + および Copilot Enterprise サブスクリプションユーザー向けに提供されており、この機能を使用すると GitHub Actions の分数や Copilot の高度なリクエスト数が消費され、プランに含まれる権利から計算されます。2025 年 6 月 4 日から、Copilot コーディングアシスタントの各モデルリクエストは 1 つの高度なリクエストを使用します。これはプレビュー機能であり、将来的に変更される可能性があります。
#Github #Copilot #AI
GitHub Copilot コーディングエージェントの公開プレビュー - GitHub Changelog
Komiko#
Komiko は、漫画、イラスト、アニメ作品の創作支援に特化したワンストップ AI プラットフォームです。このプラットフォームは Caffelabs チームによって開発され、さまざまな強力な AI ツールを統合し、アーティストやクリエイターが迅速かつ効率的にアイデアを現実の作品に変える手助けをします。
Komiko のコア機能には、キャラクターデザイン、漫画制作、イラスト生成、アニメーション制作が含まれます。キャラクターデザインの面では、プラットフォームは豊富なキャラクターライブラリを提供し、ユーザーは独自のオリジナルキャラクターを作成して使用でき、異なるシーンでのキャラクターの外観の一貫性を確保します。漫画制作においては、Komiko は AI 駆動のキャンバスを提供し、ユーザーは自由に漫画のコマを配置し、セリフバブルや効果を追加してストーリーの表現力を高めることができます。イラスト生成機能は、テキストから画像を生成したり、線画を自動で着色したり、画像を拡大したり、背景を削除したり、再照明したりするなど、さまざまな操作をサポートし、手作業での創作にかかる時間と労力を大幅に節約します。アニメーション制作においては、Komiko は業界最先端の AI モデル(Veo、Kling、Hailuo、Pixverse など)を活用し、キーフレームを滑らかで高品質なアニメーションに変換し、補間や動画拡大ツールを通じてプロフェッショナルなアニメーション制作プロセスを加速します。
#AI #アニメ #イラスト
Komiko – AI アニメジェネレーター | AI で漫画、マンガ、アニメを作成
git-bug#
git-bug は分散型、オフライン優先の欠陥追跡ツールで、問題、コメントなどを Git リポジトリに埋め込み、オブジェクト形式で保存します。この設計により、ユーザーは Git のプッシュおよびプル操作を通じて問題追跡データを同期できます。git-bug のコアの利点は、Git との深い統合にあり、Git の分散アーキテクチャを利用して、ユーザーはオフライン状態で問題を作成、編集、管理でき、その後シームレスにリモートリポジトリに同期できます。さらに、GitHub、GitLab などのプラットフォームとサードパーティブリッジを介して同期することもサポートしており、ユーザーはコマンドラインインターフェース(CLI)、ターミナルユーザーインターフェース(TUI)、またはウェブインターフェースを介して git-bug と対話し、自分に合った使用方法を柔軟に選択できます。
#Tools #Git
OpenAI チームが Codex を発表#
OpenAI チームは Codex を発表しました。これはクラウドベースのソフトウェアエンジニアリングエージェントツールで、codex-1 によってサポートされ、複数のタスクを並行して処理できます。Codex はソフトウェアエンジニアリングに最適化されており、強化学習を通じてさまざまな実際のコーディングタスク環境でトレーニングされ、人間のスタイルやコードレビューの好みに合ったコードを生成し、指示に正確に従い、テストが通過するまで継続的に実行します。現在、Codex は ChatGPT Pro、Enterprise、Team ユーザーに開放されており、将来的には Plus および Edu ユーザーにも対応する予定です。
ユーザーは ChatGPT のサイドバーを通じて Codex にアクセスし、新しいコーディングタスクを割り当てることができます。たとえば、機能コードの作成、コードベースに関する質問への回答、バグの修正、レビュー待ちのプルリクエストの提案などです。各タスクは独立した隔離環境で実行され、ユーザーのコードベースが事前にロードされています。Codex はファイルの読み取りと編集、テストフレームワーク、コードチェックツール、型チェッカーなどのさまざまなコマンドを実行できます。タスクの完了時間は通常 1 分から 30 分の間で、タスクの複雑さによって異なります。ユーザーは Codex の進捗をリアルタイムで監視できます。
Codex の安全性設計は非常に重要です。これは研究プレビューの形式でリリースされており、OpenAI の反復展開戦略に従っています。設計時にチームは安全性と透明性を優先し、ユーザーが出力結果を検証できるようにしています。ユーザーは引用、ターミナルログ、テスト結果を通じて Codex の作業内容を確認できます。Codex が不確実な状況やテストの失敗に直面した場合、ユーザーにこれらの問題を明確に伝え、ユーザーが賢明な決定を下せるようにします。ただし、ユーザーはエージェントが生成したすべてのコードを手動でレビューし、検証する必要があります。
codex-1 のトレーニング時、チームの主な目標はその出力が人間のコーディングの好みや基準に一致するようにすることでした。OpenAI o3 と比較して、codex-1 はより一貫してクリーンなパッチを生成でき、これらのパッチは即座に人間のレビューに準備が整っており、標準的なワークフローにシームレスに統合できます。
Codex の登場はソフトウェア開発に新たな可能性をもたらしました。OpenAI チームは内部テストや外部パートナーとの協力を通じて、Codex がさまざまなコードベース、開発プロセス、チームでどのように機能するかを探求しました。Codex は開発者が野心的なアイデアをより早く実現し、機能開発を加速し、問題をデバッグし、テストを作成および実行し、大規模なコードベースをリファクタリングするのを助けることができます。また、エンジニアがバックグラウンドで複雑なタスクを実行できるようにし、集中力を保ち、反復速度を加速します。
さらに、OpenAI チームは Codex CLI の更新版を発表しました。これは軽量のオープンソースコーディングエージェントで、ターミナルで実行できます。これは、o3 や o4-mini のモデルの強力な機能をローカルワークフローに導入し、開発者がタスクをより早く完了できるようにします。新しいバージョンの codex-1 は Codex CLI のために特別に設計された o4-mini で、より迅速なワークフローをサポートし、指示の遵守やスタイルにおいて同じ利点を保持しています。
Codex は現在研究プレビュー段階にあり、いくつかの制限があります。たとえば、フロントエンド作業に必要な画像入力機能が欠如しており、作業中にコース修正を行うことができません。しかし、モデルの能力が向上するにつれて、Codex はより複雑なタスクを処理できるようになり、開発者とのインタラクションは同僚との非同期コラボレーションにますます似てくると予想されます。
将来的に、OpenAI チームはよりインタラクティブで柔軟なエージェントワークフローを導入する予定です。開発者はタスク実行の途中で指導を提供し、エージェントと協力して実現戦略を策定し、積極的な進捗更新を受け取ることができるようになります。チームはまた、Codex を開発者の日常的に使用するツールとより深く統合する計画を立てています。たとえば、Codex CLI、ChatGPT Desktop、問題追跡システムや CI システムからタスクを割り当てることができるようになります。
#OpenAI #Codex #AI
Coinbase がハッカーが従業員を賄賂して顧客データを盗み、2000 万ドルの身代金を要求したと報告#
CNBC の報道によると、暗号通貨取引プラットフォーム Coinbase は深刻なサイバー攻撃を受けました。攻撃者は海外のカスタマーサポートスタッフに賄賂を渡し、一部の顧客データを取得し、それを元に Coinbase に 2000 万ドルの身代金を要求しました。Coinbase は 5 月 11 日に脅迫メールを受け取り、メールには攻撃者が Coinbase の顧客アカウント情報やその他の内部文書を取得したと主張していました。
Coinbase はアメリカ証券取引委員会に提出した書類でこの事件を明らかにし、データ漏洩の修復コストが最大 4 億ドルに達する可能性があると述べました。それにもかかわらず、Coinbase はこの漏洩がユーザーのパスワード、秘密鍵、または資金には関与していないと強調し、影響を受けたデータは主に顧客の名前、住所、電話番号、電子メール、一部の銀行口座番号、政府の身分証明画像、アカウント残高などの敏感情報であるとしています。Coinbase はブログで、攻撃者が一群の海外カスタマーサポートスタッフを募集し、顧客サポートシステムへのアクセス権を利用して一部の顧客アカウントデータを盗み、社会工学攻撃を実行したと述べています。
Coinbase はこのセキュリティの脆弱性を発見した後、直ちに関与した従業員を解雇し、影響を受ける可能性のある顧客に警告を発し、詐欺監視保護措置を強化しました。さらに、Coinbase は身代金を支払わないとし、攻撃者の逮捕と有罪判決に役立つ情報を提供するための 2000 万ドルの報奨基金を設立しました。
Coinbase はアメリカ最大の暗号通貨取引プラットフォームであり、最近暗号派生商品取引所 Deribit を買収したと発表し、S&P 500 指数に上場する予定です。このセキュリティの課題に直面しているにもかかわらず、Coinbase の CEO ブライアン・アームストロングは、同社が今後 5〜10 年以内に世界のリーディング金融サービスアプリケーションになることを目指していると述べています。
#暗号 #安全
Coinbase がハッカーが従業員を賄賂して顧客データを盗み、2000 万ドルの身代金を要求したと報告
Material 3 Expressive、より良く、よりシンプルで、より感情的なユーザー体験#
Google Design チームは、Material 3 Expressive デザインシステムの開発プロセスと核心理念について詳しく説明しています。Material 3 Expressive は、Google デザインシステムの中で最も徹底的に研究された更新版であり、そのデザイン理念はユーザーの感情駆動体験の探求に基づいています。
2022 年、Google の研究インターンは、Google アプリにおける Material Design に対するユーザーの感情的フィードバックを研究する中で、アプリインターフェースの均質化と感情表現の欠如についての議論を引き起こしました。その後、チームは 3 年間の研究とデザインの反復を通じて 46 件の独立した研究を行い、18000 人以上のグローバル参加者を対象に数百のデザイン案をテストし、最終的に Material 3 Expressive デザイン原則を形成しました。これらの原則は堅実なユーザー研究に基づいており、長期的な使いやすさのベストプラクティスに従い、デザイナーが美しくかつ高度に使える製品を構築するのを助けることを目的としています。
Material 3 Expressive の核心は感情的デザインであり、色、形、サイズ、動き、レイアウトなどのデザイン要素を通じてユーザーの感情を刺激し、同時にユーザーが目標を達成するのを助けます。研究によれば、感情的デザインはすべての年齢層のユーザーに強い好まれ、特に 18 歳から 24 歳のユーザー群では 87%の好まれ度を示しています。これらのユーザーは、感情的デザインが「視覚的魅力」と「使用意欲」において優れたパフォーマンスを発揮すると考えています。
研究の過程で、チームはさまざまな方法を採用しました。たとえば、視線追跡、調査、フォーカスグループ、実験、使いやすさテストなどです。進捗インジケーターをテストする際、チームはどのデザインが待機時間を短く感じさせるかを評価し、高級スマートフォンのデザインスタイルに合致させることを目指しました。ボタンのサイズを研究する際、チームはクリック速度を向上させることと、インターフェース要素の干渉を避けることのバランスを見つけることを目指しました。さらに、チームは新しい浮動ツールバーに関しても多くの研究を行い、その現代的でシンプルで活気に満ち、使いやすいデザインを最適化しました。
感情的デザインは製品の視覚的魅力を高めるだけでなく、ブランドの現代性と関連性を大幅に向上させる役割を果たします。研究によれば、Material 3 Expressive デザインを採用した製品は「サブカルチャー認識」において 32%、現代性において 34%、反抗性において 30%の向上を示しています。これらのデータは、感情的デザインがブランドをより先進的で革新的にし、伝統を打破する勇気を持たせることができることを示しています。
さらに重要なのは、感情的デザインがユーザー体験の向上において重要な役割を果たしていることです。視線追跡実験において、参加者は Material 3 Expressive デザインのアプリを使用する際に、重要な UI 要素により早く注意を向けることができ、従来のデザインよりも 4 倍速くなりました。たとえば、電子メールアプリでは、新しい「送信」ボタンが大きく、位置が下にあり、補助色が使用されているため、ユーザーはそのボタンをより早く見つけてクリックできるようになりました。さらに、感情的デザインは異なる年齢層のユーザー間の視覚的な位置決め時間の差を縮小し、45 歳以上のユーザーが若いユーザーと同じくらい迅速に重要なインタラクション要素を見つけられるようにします。
感情的デザインは多くの利点をもたらしますが、すべてのシーンに適用できるわけではありません。たとえば、伝統的な UI パターンに従う必要があるアプリでは、過度の感情的デザインが使いやすさを低下させる可能性があります。したがって、デザイナーは感情的デザインを適用する際に文脈を考慮し、既存のデザインパターンや基準を尊重する必要があります。
デザイナーが Material 3 Expressive デザインをより良く適用できるようにするために、Google Design チームは一連の提案を提供しています。まず、デザイナーに新しいデザインオプションを試すことを奨励し、更新された Figma Material 3 デザインツールキットを使用することを推奨します。次に、ユーザーのコアジャーニーに基づいて、感情的デザイン戦略を柔軟に活用することを提案します。さらに、ユーザーのニーズに基づいて機能性とアクセシビリティ基準を優先することを強調します。最後に、継続的な研究と反復を通じて、新鮮さと親しみやすさ、楽しさと専門性のバランスを見つけることを提案します。
#Google #デザイン #Material