Pocket Flow 通过 AI 将代码库转化为易于理解的教程。#
#AI #Codebase #Tools
GitHub - The-Pocket/PocketFlow-Tutorial-Codebase-Knowledge: Pocket Flow: Codebase to Tutorial
VoltAgent#
VoltAgent,一个开源的 TypeScript AI 代理框架,简化 AI 代理应用的开发。它提供了一系列模块化构建块和工具,帮助开发者快速构建从简单聊天机器人到复杂多代理系统的各种 AI 应用。
#AI #Tools #Agents
从大型机时代到 AI Agents:迈向真正个性化技术的漫长旅程#
Sean Falconer 探讨了技术从大型机时代到 AI 代理时代的演变,以及这一过程中个人技术体验的发展。尽管过去的每一轮技术变革都曾承诺带来更个性化的体验,但直到 AI 的出现,技术才真正开始适应用户,而非让用户去适应技术。
从 20 世纪 50 年代到 70 年代的大型机时代,计算机是巨大的共享机器,用户需要适应机器的规则,通过终端输入命令,且没有个性化可言。到了 80 年代到 90 年代的桌面电脑时代,图形用户界面(GUI)的出现让用户可以通过点击图标和菜单进行操作,但软件仍然无法根据用户行为进行学习和适应,用户仍需学习如何使用软件。随后,互联网的普及让用户能够选择浏览器、浏览网站和搜索信息,但交互仍然不够个性化,推荐系统仅基于一般趋势和宽泛类别。进入 2000 年代的移动时代,智能手机通过应用程序和触摸屏技术,让用户能够随时随地获取个性化信息,但这种个性化仍然是基于规则的,而非真正的智能学习。
AI 的出现改变了这一局面。AI 不仅能够根据用户的行为和偏好提供个性化的内容,还能通过自然语言处理技术让用户以最自然的方式与技术进行交互。AI 系统通过学习用户的意图和行为模式,能够实时调整和优化用户体验。例如,Spotify 和 Netflix 利用 AI 分析用户的行为数据,为用户提供个性化的音乐和影视内容推荐,从而显著提升了用户参与度和满意度。在电商领域,亚马逊通过 AI 驱动的产品推荐系统,实现了高达 35% 的收入增长。Sephora 则结合 AI 和增强现实(AR)技术,为用户提供个性化的美妆建议,提升了用户参与度和转化率。耐克的 “Nike By You” 平台则通过 AI 为用户提供定制化的产品设计体验。
AI 技术的快速发展得益于大型语言模型(LLM)、检索增强生成(RAG)和自适应系统等技术的支撑。LLM 能够理解和生成自然语言,使用户能够以自然的方式与系统交互。RAG 技术则允许模型在生成响应之前检索实时信息,确保输出内容的准确性和时效性。自适应系统则通过监测用户行为和反馈,不断优化自身的性能和推荐效果。
随着 AI 技术的不断发展,未来的应用程序将不再仅仅是用户的服务工具,而是能够与用户共同成长和进化的伙伴。这些应用程序将通过学习用户的行为和偏好,实时调整和优化用户体验,从而提供更加自然和有用的交互方式。然而,随着技术的个性化程度不断提高,确保其公平性、透明性和可访问性也变得至关重要,以确保所有用户都能从中受益。
#AI #思考 #用户体验
From Mainframes to AI Agents: The Long Journey to Truly Personal Tech
OpenDeepWiki 源码解读#
#AI
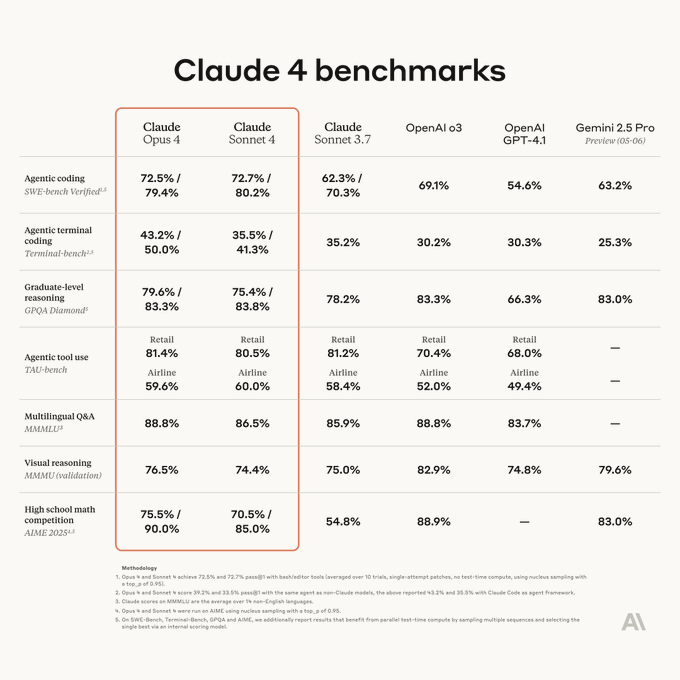
Claude 4 发布#
Claude 4 是 Anthropic 推出的下一代 AI 模型,包括 Claude Opus 4 和 Claude Sonnet 4,以下是其主要特点总结:
- 高级编程能力:Claude Opus 4 是当前最强的编程模型,在 SWE-bench 等基准测试中表现卓越,能长时间处理复杂编码任务,导航错误率从 20 % 降至近 0。支持 20 多种编程语言的代码生成与调试,适合复杂代码库管理。
- 混合推理模式:提供即时响应和扩展思考两种模式,扩展思考模式支持深入推理并结合工具使用(如网络搜索),提升复杂任务的响应质量。
- 增强的多模态能力:支持文本、图像处理,并可能扩展到视频内容分析和图像生成,适合媒体、教育和安全等领域的应用。
- 扩展的上下文窗口:保持 200 K token 的上下文窗口(约 350 页文本),适合处理长文档和复杂对话,上下文保留能力优于前代。
- 高级推理与问题解决:在研究生级推理(GPQA)、数学和逻辑任务中表现突出,推理能力较 Claude 3.5 提升 40 %,数学错误率降低 60 %。
- 伦理与安全:延续 Anthropic 的宪法 AI 方法,强化安全措施和偏见缓解,确保 AI 行为负责任,符合 GDPR 等全球法规。
- 高效性能与成本:处理速度提升 2.5 倍,保持高性能的同时成本效益高,定价为 Opus 4($15 / 百万输入 token,$75 / 百万输出 token)和 Sonnet 4($3 / 百万输入 token,$15 / 百万输出 token)。
- 企业级应用:提供 SDK、实时调试和开源插件,支持跨平台集成,适用于零售、医疗、教育等行业的复杂工作流,如数据分析、个性化体验和自动化任务。
- 多语言支持与全球化:支持多语言实时翻译和内容生成,增强全球可访问性。
- 用户体验优化:提供 “styles” 功能定制写作风格,支持内容创作和技术文档;“artifacts” 功能生成交互式内容;支持长期任务的内存优化,提升连续性。
局限性:视觉识别能力可能不如 Gemini 2.5,需更精确的提示工程以充分发挥性能。
Claude 4 在编程、推理和多模态能力上显著提升,强调伦理 AI 和企业应用,适合需要深度推理和复杂任务处理的场景。
#Claude #AI
Anthropic 发布 Claude Opus 4 和 Claude Sonnet 4。#
Claude Opus 4 是迄今为止最强大的模型,也是世界上最好的编码模型。
Claude Sonnet 4 比其前代产品有了重大升级,提供了卓越的编码和推理能力。
#Claude #AI
利用新的生成媒体模型和工具激发创造力#
谷歌 DeepMind 团队发布了一系列新的生成式媒体模型和工具,旨在激发创意并为创作者提供更多表达手段。这些模型包括 Veo 3、Imagen 4 和 Flow,它们在图像、视频和音乐生成方面取得了显著突破,能够帮助艺术家将创意愿景变为现实。
Veo 3 是谷歌最新的视频生成模型,不仅在质量上超越了 Veo 2,还首次实现了视频与音频的同步生成,例如可以在城市街道场景中生成背景交通噪音,或在公园中生成鸟鸣声,甚至能够生成角色之间的对话。Veo 3 在文本和图像提示、真实物理效果以及精准的口型同步方面表现出色,能够根据用户的故事描述生成相应的视频片段。Veo 3 已于当天在美国上线,供 Gemini 应用程序的 Ultra 订阅用户以及 Flow 用户使用,同时企业用户也可以在 Vertex AI 上获取该模型。
Imagen 4 是谷歌最新的图像生成模型,结合了速度与精度,能够生成具有惊人细节清晰度的图像,无论是复杂的织物纹理、水滴还是动物皮毛,都能精准呈现。该模型支持多种宽高比和高达 2K 分辨率的图像生成,适用于打印或演示。此外,Imagen 4 在拼写和排版方面也有了显著提升,能够更轻松地创建贺卡、海报甚至漫画。Imagen 4 已在 Gemini 应用程序、Whisk、Vertex AI 以及 Workspace 的幻灯片、视频、文档等工具中上线,并且即将推出一个速度更快的变体,其生成速度比 Imagen 3 快 10 倍,能够更快速地探索创意。
Flow 是一款为 Veo 设计的 AI 影视制作工具,结合了谷歌 DeepMind 最先进的模型,包括 Veo、Imagen 和 Gemini。用户可以通过自然语言描述镜头,管理故事中的角色、场景、物品和风格,并将这些元素编织成精美的场景。Flow 已于当天在美国上线,供 Google AI Pro 和 Ultra 计划的订阅用户使用,未来几个月将扩展到更多国家。
此外,谷歌还宣布了 Lyria 2 的更新,这是一款音乐生成模型,能够为音乐家、制作人和词曲作者提供实验性工具,激发新的创作灵感。Lyria 2 现已通过 YouTube Shorts 和 Vertex AI 向创作者和企业用户开放。谷歌还推出了 Lyria RealTime,这是一个交互式音乐生成模型,能够实时生成、控制和表演生成式音乐,用户可以通过 API 或 AI Studio 使用该模型。
在负责任的创作方面,谷歌自 2023 年以来通过 SynthID 水印技术标记了超过 100 亿张图像、视频、音频文件和文本,以帮助识别 AI 生成的内容,减少虚假信息和错误归因的可能性。Veo 3、Imagen 4 和 Lyria 2 生成的内容将继续带有 SynthID 水印。同时,谷歌还推出了 SynthID Detector,这是一个验证门户,用户可以上传内容以识别其中是否含有 SynthID 水印,从而判断内容是否由 AI 生成。
#Google #AI #Tools
Fuel your creativity with new generative media models and tools
Claude Code SDK#
Anthropic 团队推出 Claude Code SDK,帮助开发者将 Claude Code 功能集成到应用程序中。该 SDK 当前支持命令行使用,未来将推出 TypeScript 和 Python 版本。
基本使用方面,开发者可以通过命令行以非交互模式运行 Claude Code,例如使用 -p 参数直接传递提示词,或者通过管道将输入传递给 Claude Code。此外,还可以指定输出格式为文本、JSON 或流式 JSON,以满足不同开发需求。
在高级使用场景中,SDK 支持多轮对话功能,开发者可以继续最近的对话或通过会话 ID 恢复特定对话。此外,还可以通过自定义系统提示来引导 Claude 的行为,例如指定其以特定角色(如高级后端工程师或数据库架构师)进行回答。此外,Model Context Protocol(MCP)配置允许开发者扩展 Claude Code 的功能,通过加载外部服务器提供的工具和资源,例如文件系统访问或 GitHub 集成。
CLI 选项方面,SDK 提供了丰富的命令行选项,包括非交互模式运行、指定输出格式、恢复会话、限制对话轮数、覆盖或追加系统提示等。这些选项为开发者提供了灵活的控制能力,以适应不同的开发场景。
输出格式支持多种类型。默认的文本输出仅返回响应文本;JSON 输出则包含结构化数据和元数据,如成本、持续时间和会话 ID;流式 JSON 输出则逐条返回消息,适合处理多轮对话。
消息架构方面,返回的消息严格遵循特定模式,包括助手消息、用户消息、会话初始化消息和最终结果消息。每种消息类型都包含特定字段,例如会话 ID、消息类型和子类型等。
最佳实践建议开发者使用 JSON 输出格式以便于程序解析,并通过检查退出代码和错误日志来优雅地处理错误。同时,建议利用会话管理功能维持多轮对话的上下文,并在必要时设置超时和遵守速率限制。
实际应用场景中,Claude Code SDK 可以与开发工作流深度集成,例如通过 GitHub Actions 提供自动化代码审查、创建拉取请求和问题分类等功能。Anthropic 团队还提供了完整的 CLI 文档、教程和相关资源,以帮助开发者更好地利用该 SDK。
#Claude #AI #SDK
如何让用户体验良好的同时,提高产品转化率?#
用户引导设计的初衷是帮助用户快速上手产品,降低使用门槛,但在追求转化率的过程中,有时会变成一种 “温柔的控制”,甚至可能侵犯用户的基本权益。例如,一些产品在引导用户开通会员时,将 “试用 3 天后自动续费” 的条款写得极小,而取消订阅的流程却极为复杂。这种设计虽然可能在短期内提高转化率,但长期来看会损害用户的信任感,甚至可能因违反法律法规而面临风险。
为了实现用户体验与转化率的平衡,DesignLink 提出了以下几点建议:
- 尊重用户的选择权:设计应让用户真正拥有选择的权利,而不是通过视觉或交互手段强迫用户做出决策。例如,不应将 “同意” 按钮设计得过于显眼,而将 “拒绝” 选项隐藏或弱化。同时,应提供明确的退出路径,让用户能够轻松地取消操作或稍后决定。
- 保障用户的信息透明权:在请求用户权限或收集用户数据时,必须清晰地告知用户目的、内容和后果。例如,当需要访问用户的麦克风或摄像头时,应明确说明用途,而不是仅以 “为了更好的服务体验” 为由让用户感到困惑。此外,用户协议等重要信息应使用通俗易懂的语言,避免使用过于复杂的法律术语。
- 赋予用户数据控制权:用户应能够轻松地管理自己的数据,包括导出、修改和删除。产品设计中应提供便捷的数据管理功能,让用户能够随时查看和控制自己的数据。
- 优化退出与取消流程:取消订阅或退出服务的流程应简洁明了,避免设置过多的障碍。例如,不应让用户在取消订阅时填写复杂的问卷或联系客服,而应提供一键取消的功能。同时,取消后应保留用户的数据访问权一段时间,让用户能够随时恢复服务。
设计伦理在用户体验设计中至关重要。设计师应以用户为中心,站在用户的角度思考问题,确保用户在使用产品时感到安心、自由和被尊重。例如,在设计注册、支付或分享等关键节点时,应提供清晰、易懂的选项,并设置二次确认机制,避免用户因误操作而后悔。
DesignLink 提出了建立可持续的体验与权益平衡模型的方法。例如,采用 “三段式设计审查机制”,在功能上线前确认用户是否真正需要该功能,在中期检查用户是否能够自主掌控引导流程,并在后期收集用户反馈,持续优化产品。同时,设计模型应具备公平性、可解释性、可逆性和可反馈性,确保所有用户都能顺畅使用产品,并能够随时反悔或提出意见。
#用户体验 #体验设计
Google Stitch#
Google 发布 Stitch,号称是生成出色设计和 UI 界面最简单、最快捷的产品。
Stitch 是一个 AI 驱动的工具,帮助应用程序构建器为移动和 Web 应用程序生成高质量的用户界面,并轻松将它们导出 Figma,或直接访问前端代码。
#Google #AI
谷歌今天在 I/O 2025 大会上宣布了一系列新的 AI 模型、工具和订阅服务#
生成媒体
- Veo 3 是 Google 最先进的视频生成模型,能够创建带有音效甚至对话的视频,目前在美国,Google AI Ultra 订阅用户可以通过 Gemini 应用和 Flow 使用,也可以在 Vertex AI 上进行私人预览,并将在未来几周内更广泛地推出
- Veo 2 正在获得新功能,例如参考驱动的视频(用于一致的风格和角色)、用于精确镜头调整的相机控制、用于扩展纵横比的外画以及对象添加 / 删除,现在 Flow 中提供了一些新控件,而 Vertex AI 即将提供全套控件
- Imagen 4 可生成更丰富、更细致、更准确的图像,改进文本渲染和快速结果,现已在 Gemini 应用程序、Whisk、Workspace(幻灯片、文档、视频)和 Vertex AI 中免费提供,新的快速版本即将推出
- Flow 是一款全新的 AI 电影制作工具,可让您通过自然语言和资产管理,使用 Veo、Imagen 和 Gemini 创建电影剪辑;现在可供美国的 Google AI Pro 和 Ultra 订阅用户使用
- Google 的音乐生成模型 Lyria 2 现已在 Vertex AI 中上线,用于高保真自适应音乐生成,Lyria RealTime 可作为实验性交互式音乐模型通过 Gemini API 和 Google AI Studio 使用,用于实时创作和演奏生成音乐
Gemini 应用程序
- Canvas 新增一键 “创建” 按钮,可轻松将聊天内容转换为交互式内容,例如信息图表、测验和 45 种语言的播客,而 Deep Research 现在可让您上传文件和图像,并且即将推出 Google Drive 和 Gmail 集成
- Gemini Live 相机和屏幕共享功能现已在 Android 和 iOS 上免费提供(正在推出),并将很快与日历、Keep、地图和 Tasks 等 Google 应用集成
订阅
- Google AI Pro(每月 19.99 美元)可在美国和其他国家 / 地区使用,但一些最新功能(如 Chrome 中的 Flow 或 Gemini)将首先在美国推出,并计划在更广泛的范围内推出
- Google AI Ultra(249.99 美元 / 月,新用户前三个月可享受 50% 的优惠)提供最高的使用限制、最早使用 Veo 3 和 Gemini 2.5 Pro Deep Think 等高级模型、最高限制的 Flow,以及独家使用 Agent Mode 以及 YouTube Premium 和 30TB 存储空间,现已在美国推出,更多国家即将推出
- 美国、英国、巴西、印度尼西亚和日本的大学生可以免费获得一学年的 Google AI Pro
Chrome 和代理模式下的 Gemini
- Chrome 中的 Gemini 正在桌面上推出,供美国(英语)的 Google AI Pro 和 Ultra 用户使用,以便您可以总结、澄清和获取您正在阅读的任何网页的帮助,并通过隐私控制使 Gemini 仅在您提出要求时采取行动
- 代理模式即将面向 Ultra 桌面用户推出,该模式允许 Gemini 使用 MCP 协议和自动导航在线处理复杂的目标,例如筛选列表、填写表格或根据搜索结果进行安排
人工智能在搜索中的应用
- AI 模式将以新标签页的形式在 Google 搜索中向所有美国用户推出,该模式由 Gemini 2.5 提供支持,提供更高级的推理、更长的查询、多模式搜索和即时的高质量答案,其中的 “深度搜索” 可同时进行数百次搜索并综合引用的报告
- Project Astra 的实时功能(指向你的相机,询问你所看到的内容)、Project Mariner 的代理工具(购买门票、进行预订、管理任务)以及 Gmail 或其他 Google 应用的个人上下文将进入 AI 模式,由用户控制
Gemini 2.5
- Gemini 2.5 Pro 和 2.5 Flash 是领先的编码和推理基准,Gemini 2.5 Flash 有一个新的预览版本,具有更好的速度、效率和编码 / 推理能力,两种型号都将于 2025 年 6 月全面上市
- Gemini 2.5 Pro Deep Think 引入了一种实验性的增强推理模式,包括用于复杂任务的并行思维技术,在全面推出之前,首先通过 Gemini API 向值得信赖的测试人员推出,然后让用户控制答案深度和速度的思考预算
- Gemini API 和 SDK 原生支持模型上下文协议 (MCP),从而可以更轻松地跨系统集成代理和工具
- Gemini API 和 Vertex AI 现在提供 “思想摘要”,逐步解释 Gemini 的推理和工具使用
Project Starline -> Google Beam、Astra -> Gemini Live、Mariner -> 特工模式
- Starline 项目现已更名为 Google Beam,这是一个由人工智能驱动的 3D 视频通话平台,可将 2D 流媒体转化为身临其境的逼真会议,并将于今年晚些时候与惠普和其他企业合作伙伴合作推出
- Gemini Live 内置 Astra 的实时摄像头和屏幕共享功能,这些功能已在 Android 上免费提供,现已在 iOS 上推出
- Project Mariner 的代理计算机使用功能(例如多任务处理和浏览器自动化)现已面向美国 Ultra 用户开放,并将很快通过 Gemini API 和 Vertex AI 面向开发者开放
开放模型和开发工具
Gemma 3n 是一种新型高效多模态开放模型,专为快速、低内存设备设计,支持文本、音频、图像和多语言输入,目前已在 AI Studio 和 AI Edge 上为开发者提供预览版。
- Jules 是一款由 Gemini 2.5 Pro 提供支持的异步编码代理,目前处于公开测试阶段,并且免费,可在 GitHub 或您的 repo 中处理实际的编码任务,并具有并发任务和音频更新日志
- Gemini Diffusion 是一种用于快速文本生成的实验性研究模型,其输出速度约为 Google 之前最快模型的五倍,目前已通过候补名单向开发者提供预览。
SynthID Detector 是一个用于检查图像、音频、视频或文本是否由 Google 的 AI 工具生成的门户,目前正通过候补名单向早期测试人员推出,后续将提供更广泛的访问权限
AlphaEvolve:基于 Gemini 的编码代理,用于设计高级算法#
AlphaEvolve,一个由 Gemini 模型驱动的进化型编码智能体,专门用于通用算法的发现与优化。AlphaEvolve 结合了 Gemini Flash 和 Gemini Pro 两种大型语言模型(LLM)的能力,前者注重广度探索,后者提供深度建议,共同提出实现算法解决方案的计算机程序代码。通过自动化评估器验证、运行和评分这些程序,AlphaEvolve 在数学和计算机科学等可量化领域表现出色。
AlphaEvolve 在谷歌的计算生态系统中发挥了重要作用,包括数据中心调度、硬件设计和 AI 模型训练等。例如,它为谷歌 Borg 系统发现了一种高效启发式算法,平均恢复了谷歌全球计算资源的 0.7%,显著提高了数据中心的效率。在硬件设计方面,AlphaEvolve 为谷歌的张量处理单元(TPU)提出了优化建议,提升了矩阵乘法运算的效率。此外,它还通过优化 GPU 指令,为 Transformer 模型中的 FlashAttention 核心实现了高达 32.5% 的加速。
在数学和算法发现领域,AlphaEvolve 也取得了突破性进展。它提出了一个用于矩阵乘法的新型梯度优化过程,发现了多种新算法。例如,它找到了一种将 4×4 复值矩阵相乘仅需 48 次标量乘法的算法,优于此前被认为最佳的 Strassen 算法。此外,AlphaEvolve 在 50 多个数学分析、几何、组合学和数论的开放问题中进行了测试,约 75% 的情况下重新发现了已知的最优解,而在 20% 的情况下改进了已知的最佳解决方案,例如在 11 维空间中为 “接吻数问题” 建立了新的下界。
#Google #AI #Gemini #Agents
AlphaEvolve: A Gemini-powered coding agent for designing advanced algorithms
SMS 2FA 不仅不安全,而且对山区居民不友好#
stillgreenmoss 描述了居住在北卡罗来纳州西部山区的一位老年女士因短信双因素认证(SMS 2FA)所面临的问题。这位女士生活在山区,尽管距离城镇仅 20 分钟车程,但她的住所由于地形原因无法接收到稳定的手机信号。她使用 Spectrum 提供的网络服务和手机套餐,但由于山区信号覆盖不足,她无法接收用于登录账户的短信验证码,导致无法访问诸如电子邮件、银行账户和医疗保健等重要服务。
尽管她启用了手机的 Wi-Fi 通话功能,但发现来自五位数字短码的短信验证码仍然无法通过 Wi-Fi 接收。stillgreenmoss 进一步调查发现,某些互联网服务提供商(ISP)提供的座机服务可以接收短信并由计算机语音读出,但 Spectrum 并不提供此类服务。为了能够正常使用这些服务,她需要将所有依赖 SMS 2FA 的账户改为使用基于时间的一次性密码(TOTP)认证,但这需要她先登录账户才能更改设置。因此,她不得不列出所有因 SMS 2FA 而无法访问的网站,然后与朋友约定见面,前往城镇,在朋友的帮助下逐一将这些账户改为 TOTP 认证。然而,部分网站不支持 TOTP,她还需要联系这些公司,请求关闭她账户的 SMS 2FA 功能,但发现如今很难与公司取得联系。
stillgreenmoss 指出其他解决办法包括将手机号码转移到支持 Wi-Fi 接收短码短信的 VoIP 提供商,或者花费数百美元在住所外安装手机信号增强器,甚至考虑搬家,这些选项都显得非常不合理。此外,尽管 TOTP 是一种替代方案,但需要下载专门的应用程序,且用户在选择应用时会面临众多高风险的选择和复杂的技术说明。
尽管 SMS 2FA 在用户体验方面表现良好,且在技术上足够安全,但其在山区的适用性极差。据估计,北卡罗来纳州西部山区有 110 万人口,整个阿巴拉契亚地区有 2500 万人口,以及更多居住在西部山脉和太平洋沿岸山脉的人群,他们都面临着类似的手机信号覆盖不足的问题。stillgreenmoss 质疑,尽管这些地区有互联网接入,但 F 级别的手机信号覆盖使得 SMS 2FA 对于这些用户来说几乎无法使用,这凸显了 SMS 2FA 在特定地理环境下的局限性。
#2FA #安全
SMS 2FA is not just insecure, it's also hostile to mountain people — stillgreenmoss
PDF 转文本,一个具有挑战性的问题#
Marginalia 探讨了从 PDF 文件中提取文本信息的复杂性以及为搜索引擎优化文本提取的方法。团队指出,PDF 文件本质上是一种图形格式而非文本格式,其内容是字符映射到纸张上的坐标,字符可能旋转、重叠且顺序混乱,缺乏语义信息,这使得提取文本变得极具挑战性。尽管如此,用户仍能在 PDF 查看器中使用搜索功能,这本身就是一个值得惊叹的成就。
搜索引擎更倾向于接收干净的 HTML 格式输入,而目前最佳的 PDF 转文本方法可能是基于视觉的机器学习模型,但这种方法难以在没有 GPU 的单服务器上处理数百 GB 的 PDF 文件。因此,团队选择从 Apache PDFBox 的 PDFTextStripper 类入手,虽然该类能够提取 PDF 中的文本,但存在诸多限制,例如无法识别标题等语义信息,而这些信息对于搜索引擎来说至关重要。
为了使 PDF 转文本提取更适合搜索引擎的需求,团队进行了多项改进。在识别标题方面,一种简单的方法是寻找半粗体或更粗的文本行,但并非所有标题都使用加粗字体,许多标题依赖于字体大小来区分。由于不同文档的字体大小差异较大,因此无法找到一个全局的断点来区分标题和正文,而是需要针对每页构建字体大小统计信息。通过分析页面的字体大小分布,可以发现每页通常有一个主导字体大小,即正文文本的字体大小。在提取标题时,将页面中位数字体大小的 20% 作为因子,能够较为可靠地识别标题,尽管存在一些例外情况。
此外,标题有时会分成多行,团队尝试将连续的标题行合并为一行,但这一操作的决策较为复杂。例如,某些标题可能右对齐,或者标题下方紧跟着作者姓名等其他加粗文本,这些情况都增加了合并标题的难度。尽管如此,将具有相同字体大小和权重的连续标题行合并通常能够取得较好的效果,但也会产生一些不理想的结果。
在识别段落方面,PDFTextStripper 在识别段落方面表现不错,它通过分析行间距和缩进来判断何时分段,但其行间距逻辑仍有改进空间。该工具使用固定的行间距断点,未考虑不同文档的行间距差异,尤其是在学术草稿和预印本中,1.5 至 2 倍的行间距较为常见。如果行间距值过大,可能会干扰标题识别,导致某些标题被误归入正文段落。为解决这一问题,团队再次采用与字体大小类似的统计方法。通过分析页面文本的行间距分布,可以发现中位数行间距正是正文文本所使用的行间距,因此可以在此基础上添加一个因子,从而得到一种能够适应任何行间距的段落分隔启发式方法。
从 PDF 中提取文本永远不会完美无缺,因为该格式并非为提取文本而设计,且在选择 “足够好” 的解决方案时需要权衡利弊。搜索引擎主要关注相关性信号,例如标题,如果能够识别摘要并大致理解剩余文本的结构,就可以认为这是一种相对优雅的解决方案。
#PDF #实践
PDF to Text, a challenging problem
GitHub Copilot 编码助手公开预览版#
GitHub Copilot 编码助手于 2025 年 5 月 19 日正式进入公开预览阶段,为开发者带来全新的编程体验。开发者可以像分配给其他开发者一样将问题分配给 Copilot,它会在后台运行,利用 GitHub Actions 提供的云端开发环境,探索代码仓库、进行修改,并通过测试和代码规范验证后提交代码。完成任务后,Copilot 会通知开发者进行代码审查,开发者可以通过在拉取请求中留言要求 Copilot 进行修改,或者在本地分支中继续开发,Copilot 会全程协助。
Copilot 在处理低到中等复杂度的任务时表现优异,例如在经过良好测试的代码库中添加功能、修复漏洞、扩展测试、重构代码以及改进文档等,甚至可以同时处理多个问题。该功能目前面向 Copilot Pro+ 和 Copilot Enterprise 订阅用户开放,使用该功能会消耗 GitHub Actions 分钟数和 Copilot 高级请求次数,从计划中包含的权益开始计算。从 2025 年 6 月 4 日起,Copilot 编码助手每次模型请求将使用一个高级请求,这是一项预览功能,未来可能会发生变化。
#Github #Copilot #AI
GitHub Copilot coding agent in public preview - GitHub Changelog
Komiko#
Komiko 是一个一站式 AI 平台,专注于为创作者提供漫画、插画和动漫作品的创作支持。该平台由 Caffelabs 团队开发,整合了多种强大的 AI 工具,旨在帮助艺术家和创作者快速高效地将创意转化为现实作品。
Komiko 的核心功能包括角色设计、漫画创作、插画生成和动画制作。在角色设计方面,平台提供了丰富的角色库,用户可以创建并使用自己的原创角色,确保角色在不同场景下的外观一致性。对于漫画创作,Komiko 提供了 AI 驱动画布,用户可以在其上自由排布漫画分格,添加对话气泡和效果,增强故事表现力。插画生成功能则支持文本生成图像、线稿自动上色、图像放大、背景移除和重新打光等多种操作,大幅节省了人工创作的时间和精力。在动画制作方面,Komiko 利用了行业领先的 AI 模型,如 Veo、Kling、Hailuo 和 Pixverse 等,能够将关键帧转化为流畅、高质量的动画,并通过补帧和视频放大工具加速专业动画制作流程。
#AI #动漫 #插画
Komiko – AI Anime Generator | Create Comics, Manga and Anime with AI
git-bug#
git-bug 是一个分布式、离线优先的缺陷跟踪工具,它将问题、评论等嵌入到 Git 仓库中,以对象形式存储,而非文件形式。这种设计使得用户能够通过 Git 的推送和拉取操作来同步问题跟踪数据。git-bug 的核心优势在于其与 Git 的深度集成,借助 Git 的分布式架构,用户可以在离线状态下创建、编辑和管理问题,之后再无缝同步到远程仓库中。此外,它还支持与 GitHub、GitLab 等平台通过第三方桥接进行同步,用户可以通过命令行界面(CLI)、终端用户界面(TUI)或网页界面与 git-bug 交互,灵活选择适合自己的使用方式。
#Tools #Git
OpenAI 团队发布 Codex#
OpenAI 团队发布了 Codex,一个基于云端的软件工程代理工具,能够并行处理多项任务,由 codex-1 提供支持。Codex 针对软件工程进行了优化,通过强化学习在多种真实编码任务环境中进行训练,能够生成符合人类风格和代码审查偏好的代码,精确遵循指令,并且可以持续运行测试直到通过。目前,Codex 已向 ChatGPT Pro、Enterprise 和 Team 用户开放,未来也将支持 Plus 和 Edu 用户。
用户可以通过 ChatGPT 的侧边栏访问 Codex,为其分配新的编码任务,例如编写功能代码、回答代码库相关问题、修复漏洞以及提出待审查的拉取请求等。每个任务都在独立的隔离环境中运行,预加载了用户的代码库。Codex 可以读取和编辑文件,运行包括测试框架、代码检查工具和类型检查器在内的各种命令。任务完成时间通常在 1 到 30 分钟之间,具体取决于任务的复杂性,用户可以实时监控 Codex 的进度。
Codex 的安全性设计至关重要。它以研究预览的形式发布,遵循 OpenAI 的迭代部署策略。在设计时,团队优先考虑了安全性和透明性,使用户能够验证其输出结果。用户可以通过引用、终端日志和测试结果来检查 Codex 的工作内容。当 Codex 遇到不确定的情况或测试失败时,会明确告知用户这些问题,以便用户做出明智的决策。不过,用户仍需手动审查并验证所有由代理生成的代码,然后才能进行集成和执行。
在训练 codex-1 时,团队的主要目标是使其输出与人类的编码偏好和标准保持一致。与 OpenAI o3 相比,codex-1 能够更一致地生成更干净的补丁,这些补丁已准备好可立即进行人类审查,并且能够无缝集成到标准工作流程中。
Codex 的推出为软件开发带来了新的可能性。OpenAI 团队通过内部测试和与外部合作伙伴的协作,探索了 Codex 在不同代码库、开发流程和团队中的表现。Codex 能够帮助开发者更快地实现雄心勃勃的想法,加速功能开发、调试问题、编写和执行测试以及重构大型代码库。它还可以让工程师在后台运行复杂的任务,从而保持专注并加快迭代速度。
此外,OpenAI 团队还发布了 Codex CLI 的更新版本,这是一个轻量级的开源编码代理,可在终端中运行。它将类似 o3 和 o4-mini 的模型的强大功能引入本地工作流程,使开发者能够更快地完成任务。新版本的 codex-1 是为 Codex CLI 特别设计的 o4-mini,支持更快的工作流程,并且在指令遵循和风格方面保持了相同的优势。
Codex 目前处于研究预览阶段,仍有一些限制,例如缺乏前端工作所需的图像输入功能,以及无法在工作时进行课程纠正。不过,随着模型能力的提升,预计 Codex 将能够处理更复杂的任务,并且与开发者的交互将越来越类似于与同事的异步协作。
未来,OpenAI 团队计划引入更具互动性和灵活性的代理工作流程。开发者将能够在任务执行中途提供指导,与代理合作制定实现策略,并接收主动的进度更新。团队还计划将 Codex 与开发者日常使用的工具进行更深入的集成,例如从 Codex CLI、ChatGPT Desktop 或问题跟踪器和 CI 系统中分配任务。
#OpenAI #Codex #AI
Coinbase 称黑客贿赂员工窃取客户数据并索要 2000 万美元赎金#
根据 CNBC 的报道,加密货币交易平台 Coinbase 遭遇了一起严重的网络攻击事件。攻击者通过贿赂海外客服人员,获取了部分客户数据,并以此向 Coinbase 索要 2000 万美元的赎金。Coinbase 在 5 月 11 日收到了一封勒索邮件,邮件中声称攻击者已经获取了部分 Coinbase 客户账户信息以及其他内部文件,包括与客户服务和账户管理系统相关的资料。
Coinbase 在向美国证券交易委员会提交的文件中披露了这一事件,并表示此次数据泄露可能涉及的修复成本高达 4 亿美元。尽管如此,Coinbase 强调,此次泄露并未涉及用户的密码、私钥或资金,受影响的数据主要包括客户姓名、地址、电话号码、电子邮件、部分银行账户号码、政府身份识别图像以及账户余额等敏感信息。Coinbase 在其博客中提到,攻击者招募了一群海外客服人员,利用其对客户支持系统的访问权限,窃取了部分客户账户数据,以便实施社会工程学攻击。
Coinbase 在发现这一安全漏洞后,立即解雇了涉事员工,并向可能受到影响的客户发出警告,同时增强了欺诈监控保护措施。此外,Coinbase 表示不会支付赎金,而是设立了 2000 万美元的奖励基金,用于提供有助于逮捕和定罪此次攻击者的线索。
Coinbase 是美国最大的加密货币交易平台,近期刚刚宣布收购加密衍生品交易所 Deribit,并即将进入标普 500 指数。尽管面临此次安全挑战,Coinbase 的首席执行官 Brian Armstrong 仍表示,公司有志在未来五到十年内成为全球领先的金融服务应用。
#币圈 #安全
Coinbase says hackers bribed staff to steal customer data and are demanding $20 million ransom
Material 3 Expressive,更好、更简单、更情感化的用户体验#
Google Design 团队详细介绍了 Material 3 Expressive 设计系统的研发过程与核心理念。Material 3 Expressive 是 Google 设计系统有史以来经过最深入研究的更新版本,其设计理念源于对用户情感驱动体验的探索。
2022 年,Google 的研究实习生在研究用户对 Google 应用中 Material Design 的情感反馈时,引发了团队对应用界面同质化与缺乏情感表达的讨论。随后,团队通过三年的研究与设计迭代,开展了 46 项独立研究,涉及超过 18000 名全球参与者,测试了数百种设计方案,最终形成了 Material 3 Expressive 设计原则。这些原则基于坚实的用户研究,并遵循长期的可用性最佳实践,旨在帮助设计师打造出既美观又高度可用的产品。
Material 3 Expressive 的核心在于情感化设计,它通过色彩、形状、大小、运动和布局等设计元素激发用户情感,同时帮助用户实现目标。研究表明,情感化设计受到各年龄段用户的强烈偏好,尤其是在 18 至 24 岁的用户群体中,偏好度高达 87%。这些用户认为情感化设计在 “视觉吸引力” 和 “使用意愿” 方面表现突出。
在研究过程中,团队采用了多种方法,包括眼动追踪、调查与焦点小组、实验以及可用性测试。例如,在测试进度指示器时,团队评估了哪些设计能让等待时间感觉更短,同时又符合高端手机的设计风格;在研究按钮大小时,团队寻求在提高点击速度与避免界面元素相互干扰之间找到平衡。此外,团队还对新的浮动工具栏进行了多项研究,优化其现代、简洁、充满活力且易于使用的设计。
情感化设计不仅提升了产品的视觉吸引力,还显著提升了品牌的现代感与相关性。研究表明,采用 Material 3 Expressive 设计的产品在 “亚文化感知” 方面提升了 32%,在 “现代性” 方面提升了 34%,在 “叛逆性” 方面提升了 30%。这些数据表明,情感化设计能够让品牌显得更前沿、更创新,并且敢于突破传统。
更重要的是,情感化设计在提升用户体验方面发挥了关键作用。通过眼动追踪实验,参与者在使用 Material 3 Expressive 设计的应用时,能够更快地注意到关键 UI 元素,速度比传统设计快了四倍。例如,在电子邮件应用中,新的 “发送” 按钮更大、位置更靠下且使用了辅助色,使得用户能够更快地找到并点击该按钮。此外,情感化设计还缩小了不同年龄段用户之间的视觉定位时间差距,使 45 岁以上的用户能够与年轻用户一样快速地找到关键交互元素。
尽管情感化设计带来了诸多好处,但它并非适用于所有场景。例如,在某些需要遵循传统 UI 模式的应用中,过度的情感化设计可能会导致可用性下降。因此,设计师在应用情感化设计时需要考虑上下文,尊重已有的设计模式和标准。
为了帮助设计师更好地应用 Material 3 Expressive 设计,Google Design 团队提供了一系列建议:首先,鼓励设计师尝试新的设计选项,如更新后的 Figma Material 3 设计工具包;其次,建议设计师结合用户的核心旅程,灵活运用情感化设计策略;此外,强调从用户需求出发,优先考虑功能性和遵循无障碍标准;最后,建议通过持续的研究和迭代,找到新鲜感与熟悉度、趣味性与专业性之间的平衡。
#Google #设计 #Material
Expressive Design: Google's UX Research - Google Design